1. Introduction
Large Language Models (LLMs) like GPT, LLaMA, and Claude are powerful AI systems trained to understand and generate human-like text.
Their training involves feeding huge amounts of text data into deep neural networks so the model learns patterns, context, and meaning.
2. The Training Pipeline
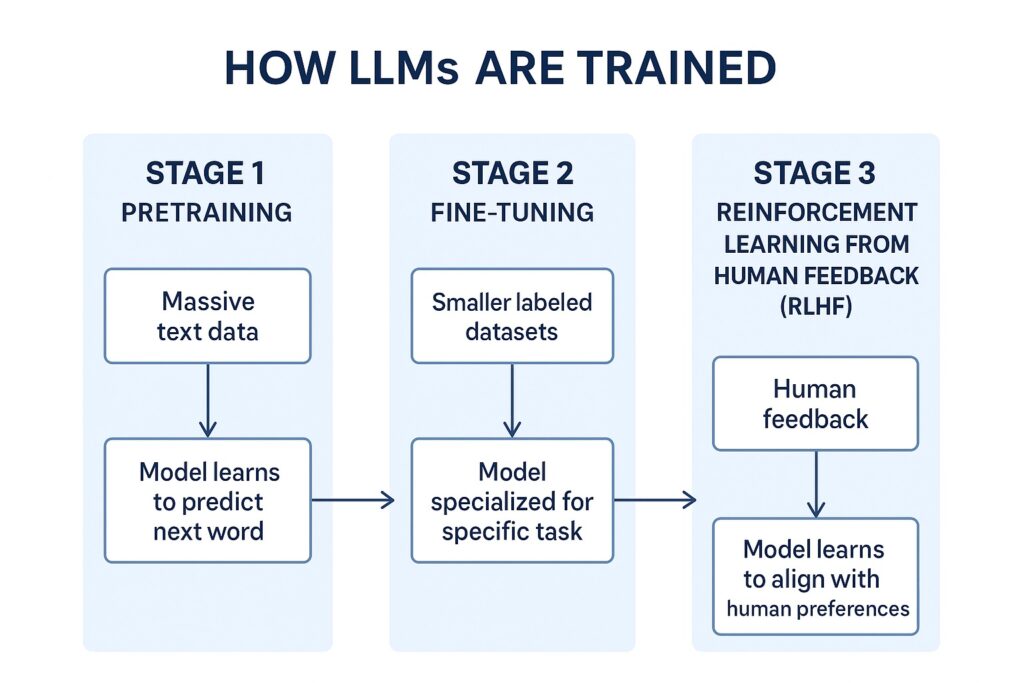
LLM training generally has three main stages:
Stage 1: Pretraining
- Goal: Teach the model general language understanding.
- Method: The model is given massive datasets (books, websites, articles) and learns to predict the next word in a sentence.
- Example: cssCopyEdit
Input: "The cat is sitting on the" Target Output: "mat" - Dataset Size: Often in hundreds of billions of words.
- Outcome: The model learns grammar, facts, and general reasoning patterns.
Stage 2: Fine-Tuning
- Goal: Make the model good at specific tasks or domains.
- Method: Use smaller, curated datasets with labeled examples.
- Example: For medical AI, train with medical texts, Q&A pairs, etc.
- Outcome: The model becomes more accurate for a targeted application.
Stage 3: Reinforcement Learning from Human Feedback (RLHF)
- Goal: Align the model’s behavior with human preferences.
- Method:
- Human labelers rank multiple AI outputs for a prompt.
- Train a “reward model” based on these rankings.
- Use reinforcement learning to adjust the LLM to prefer better responses.
- Example:
- Question: “Explain quantum physics to a 10-year-old.”
- Humans rank responses from simplest to most complex.
- Outcome: The model becomes safer, more helpful, and user-friendly.
3. Core Ingredients for Training
- Data: Quality + diversity of text data.
- Model Architecture: Typically Transformer-based (multi-head attention).
- Compute Power: Requires thousands of GPUs or TPUs.
- Optimization Algorithms: AdamW, learning rate schedulers, gradient clipping.
- Evaluation Metrics: Perplexity, accuracy, and task-specific scores.
4. Challenges in Training
- Data bias → Can lead to biased outputs.
- Hallucinations → Model generating false but confident answers.
- Compute costs → Training GPT-4 scale models costs millions of dollars.
- Ethics & Safety → Preventing harmful or unsafe use.
5. Summary Table
| Stage | Purpose | Data Type | Example Use |
|---|---|---|---|
| Pretraining | General language learning | Massive raw text | Grammar, facts |
| Fine-tuning | Specialization | Curated labeled data | Legal AI, Medical AI |
| RLHF | Human alignment | Ranked responses | Safety, helpfulness |